When we are dealing with URL encode in .NET Core 2.1, there are two APIs: System.Net.WebUtility.UrlEncode and System.Web.HttpUtility.UrlEncode. What's the difference between them? And which one should we prefer to use? I have done some research today, here's my findings.
Test Results
First, let's see some tests. I've tested 2 couples of the same method between WebUtility class and HttpUtility class: UrlEncode/UrlDecode and HtmlEncode/HtmlDecode
The only difference is the UrlEncode(string) function has different outputs:
var webencode = System.Net.WebUtility.UrlEncode(test);
var httpencode = System.Web.HttpUtility.UrlEncode(test);
Console.WriteLine($"WebUtility.UrlEncode: {webencode}");
Console.WriteLine($"HttpUtility.UrlEncode: {httpencode}");The result is WebUtility.UrlEncode() is using lowercase while HttpUtility.UrlEncode() outputs UPPERCASE for the encoded characters.
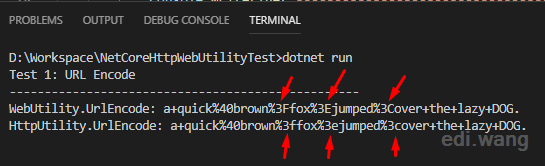
Why the heck is that?
Thanks to Microsoft for open sourcing .NET, we can find out the root cause by looking into the .NET Core source code here: https://github.com/dotnet/corefx
If you want to see for yourself, here's the source code locations:
WebUtility class "\corefx\src\System.Runtime.Extensions\src\System\Net\WebUtility.cs"
HttpUtility class "\corefx\src\System.Web.HttpUtility\src\System\Web\HttpUtility.cs"
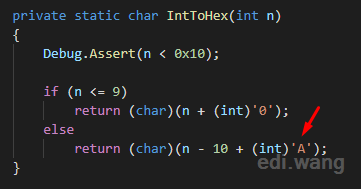
WebUtility
I found the UrlEncode method at line 408 (this may change if Microsoft updates the source code)
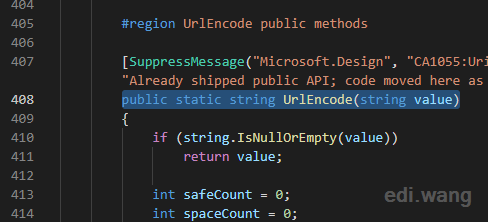
It will internally calls GetEncodedBytes() method near the end.
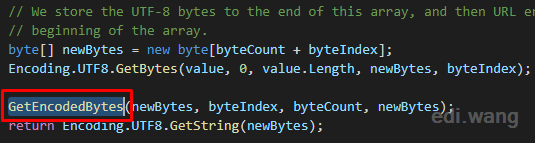
It then calls IntToHex() method.
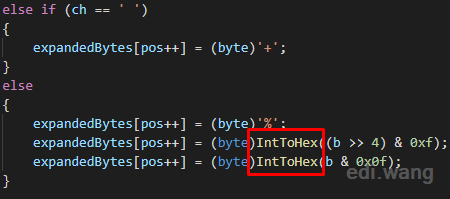
Finally, the heck is because it is casting an UPPERCASE character 'A', this is why every encoded character is returning as UPPERCASE.
HttpUtility
I did the similar research to HttpUtility, and found it finally calls System.Web.Util.IntToHex() method, which is:
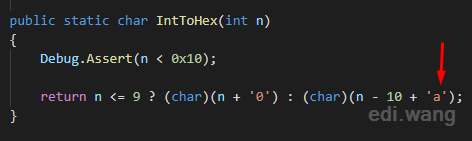
This explains why it is returning lowercase letters.
My guess
I don't know if this is intentionally by design or not, but having two versions of IntToHex() does not make sense to me. I would prefer to have an optional parameter to let API users control the encoding casing.
Which one should we prefer to use?
In short, I use lowercase for URLs across my entire system. So, I will choose HttpUtility.UrlEncode() to encode the URLs.
In Windows, UPPERCASE or lowercase in URLs does not matter. But in Linux, it is different, you can result in a 404 page. Besides, the HASHes for the UPPERCASE string and lowercase string are different. If somewhere in the system when there is a validation to check the URL's hash, it can fail because of case sensitivity regardless in Windows or Linux.
For SEO, some people may hear lowercase is better, but for Google, casing does not impact rankings, you can check the discussion here.
The point is you should use consistent URL casing across your own system, and be aware of the other systems you are talking to if they treats URL casing differently.
Many thanks. We where test crawling our website and noticed a difference in the URLs. Now we know why :) It's already hard to keep consistency when developing applications in a team. Now even need to be more careful with selecting which UrlEncode to use by default.
I went with Uri.EscapeUriString()
Great post!
Maybe not directly related to this, but can be considered as a relevant tip for people looking at this post.
It's more accurate to encode the
Query Stringparameters which can possible have special characters, rather than encoding fullURL.OAuth expects url encoding in upper case
https://www.codeproject.com/Articles/75424/Step-by-Step-Guide-to-Delicious-OAuth-API#5
The specification for URIs [RFC1738] explicitly states upper case:
In addition, octets may be encoded by a character triplet consisting of the character "%" followed by the two hexadecimal digits (from "0123456789ABCDEF") which forming the hexadecimal value of the octet. (The characters "abcdef" may also be used in hexadecimal encodings.)
Source: https://tools.ietf.org/html/rfc1738#section-2.2
As I went through the article just realized the author is my teammate :)
Thank you, Edi.
They do behave differently. I ran into this issue myself when two different Azure components were using different URL encoding methods so the encoded value used later as a cache key ended up in lookup failures.
It is probably safest and most appropriate to now be using Uri.EscapeDataString().
As of .NET 6, the Uri.EscapeUriString() has been deprecated and there is a warning on the documentation page: https://learn.microsoft.com/en-us/dotnet/api/system.uri.escapeuristring?view=net-6.0 "Caution
Uri.EscapeUriString can corrupt the Uri string in some cases. Consider using Uri.EscapeDataString for query string components."