Problem
I am upgrading a 16-year-old legacy application from .NET Framework to .NET 6 these days. There is a custom encryption method that uses Encoding.Default.GetChars() method, which output wrong result in .NET 6.
// .NET 6.0 output: �
// .NET Framework output: „
Encoding.Default.GetChars(new byte[] { 132 });It is well known that using Encoding.Default is a bad practice, but it is after all, a 16-year-old application, this piece of encryption method is still running at the very fundamental core of our banking system. I must keep the output the same as before. Let's see how to fix this.
Root Cause
After work 996, I found Encoding.Default is using UTF8 (65001), it is consistent on every machine with .NET 6.
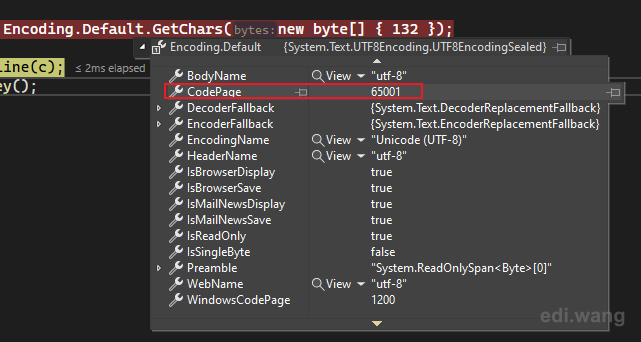
However, .NET Framework which runs only on Windows, is using the system encoding for Encoding.Default
On a English (US) version of Windows, it uses SBCSCodePageEncoding (BodyName iso-8859-1, CodePage 1252). But a Chinese version of Windows or English version of Windows with Chinese set as non-Unicode programs. It will use GB2312 (936), which will output another result.
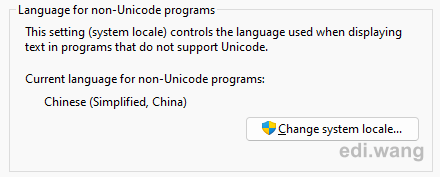
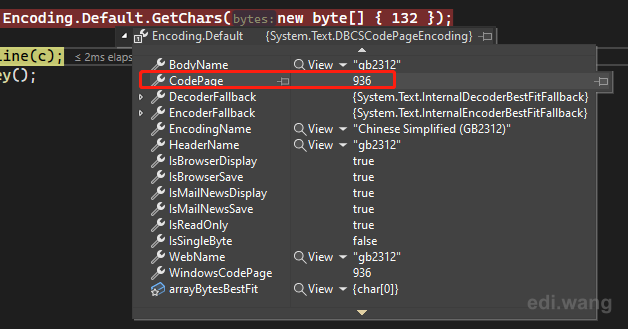
Our datacenters happen to be using only English version of Windows Server for decades, and we don't change system locale. So, this potential bug that can blow our banking system sky high never happened before. Pure luck!
Fix
In both .NET 6 and .NET Framework, we can explicitly set encoding by Encoding.GetEncoding() method. In my case, the change code to
Encoding.GetEncoding(1252).GetChars(new byte[] { 132 })There is still one thing to notice. In .NET 6.0, code page 1252 is not included by default, so you will need to register encoding providers first.
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);Now we can get same output on every system regardless of their system level locale!

Thanks a lot for this post, I spent like 3 hours trying to figure out from where the problem presented itself and this solution is not only working but really helpful to standardize our encription method throughout all the projects in different .net versions, thank you again fellow stranger!