Windows 10里面有个脑残设计,就是系统默认的CharacterGroupings类型在中文版系统上会产生除了A-Z字母以外的带“拼音”前缀的另外24个分组。比如开屎菜单里就是这样:

如果我们用这个CharacterGroupings类型去创建带分组的ListView,就会变成这样:
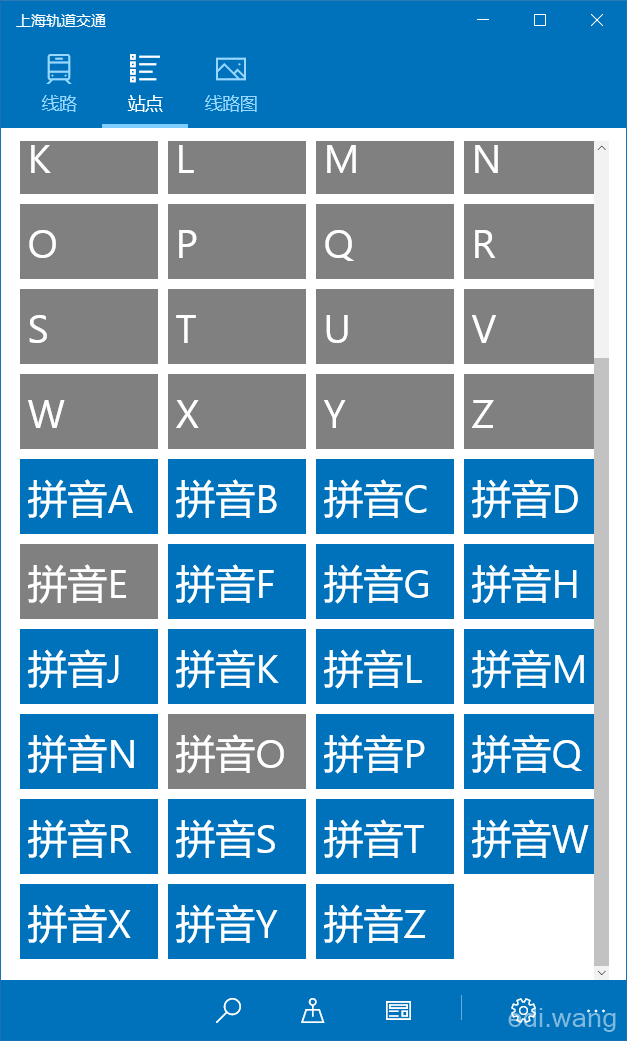
更蛋疼的是,如果用户的系统是英文语言的,他就会发现分组变成空白了,没有任何数据。用户不知道这是微软干的,又得给我们的APP打1星,还要骂我们傻逼。
今天经过研究,终于把这个问题给解决了,不仅去掉了“拼音”前缀,也不用担心用户系统是什么语言的,都能正常显示分组列表。
我们先看看原来的代码。
public class AlphaKeyGroup<T> : List<T>
{
const string GlobeGroupKey = "?";
public string Key { get; private set; }
public AlphaKeyGroup(string key)
{
Key = key;
}
private static List<AlphaKeyGroup<T>> CreateDefaultGroups(CharacterGroupings slg)
{
return (from cg
in slg
where cg.Label != string.Empty
select cg.Label == "..." ?
new AlphaKeyGroup<T>(GlobeGroupKey) :
new AlphaKeyGroup<T>(cg.Label))
.ToList();
}
public static List<AlphaKeyGroup<T>> CreateGroups(IEnumerable<T> items, Func<T, string> keySelector, bool sort)
{
CharacterGroupings slg = new CharacterGroupings();
List<AlphaKeyGroup<T>> list = CreateDefaultGroups(slg);
foreach (T item in items)
{
int index = 0;
string label = slg.Lookup(keySelector(item));
index = list.FindIndex(alphagroupkey => (alphagroupkey.Key.Equals(label, StringComparison.CurrentCulture)));
if (index > -1 && index < list.Count) list[index].Add(item);
}
if (sort)
{
foreach (AlphaKeyGroup<T> group in list)
{
group.Sort((c0, c1) => keySelector(c0).CompareTo(keySelector(c1)));
}
}
return list;
}
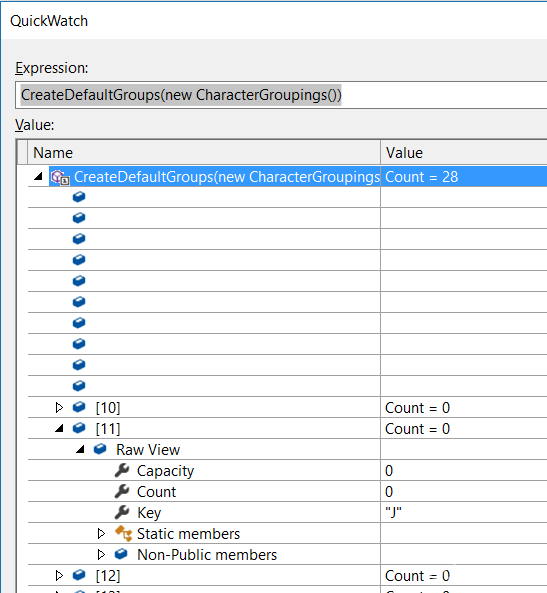
}这段代码出bug的地方就在于:CreateDefaultGroups()这个方法在中文版系统上会产生额外的“拼音”前缀的分组数据。并且在英文版系统上,slg.Lookup(keySelector(item)); 所返回的label为“漢字/汉字”,不属于任何分组。
截图:英文版系统分组
截图:针对汉字的LookUp结果
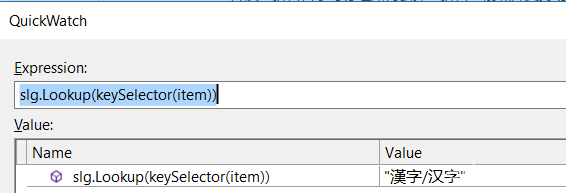
在英文版系统上并没有Key为“漢字/汉字”的分组。所以最终会得到空白列表。
所以解决这个问题的思路就是,不通过CharacterGroupings去创建分组,而让我们自己去创建一个纯英文字母的分组,这样就不会带“拼音”前缀。然后自己定义一个类似Lookup的方法,根据汉字取拼音首字母。
所以,我们先创建一个固定的A-Z分组:
private static List<AlphaKeyGroup<T>> CreateAZGroups()
{
char[] alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".ToCharArray();
var list = alpha.Select(c => new AlphaKeyGroup<T>(c.ToString())).ToList();
return list;
}
然后改掉这行代码:
List<AlphaKeyGroup<T>> list = CreateAZGroups(); //CreateDefaultGroups(slg);
现在问题来了,C#里怎么根据汉字取拼音首字母呢?
好在万能的必硬找到了一篇:http://www.cnblogs.com/glacierh/archive/2008/08/25/1276113.html
但是里面的这行代码:
System.Text.Encoding.Default.GetBytes(CnChar);
在UWP里是会爆的,没有.Default的。改成UTF8, Unicode什么的会产生不正确的拼音结果。
这时候就又要用到我的Edi.UWP.Helpers库了!!!
安装我的库之后,就可以把这行改成:
byte[] ZW = DBCSEncoding.GetDBCSEncoding("gb2312").GetBytes(cnChar);
就不会爆了。
然后把对应的地方改掉:
string label = GetCharSpellCode(keySelector(item)); //slg.Lookup(keySelector(item));
大功告成:
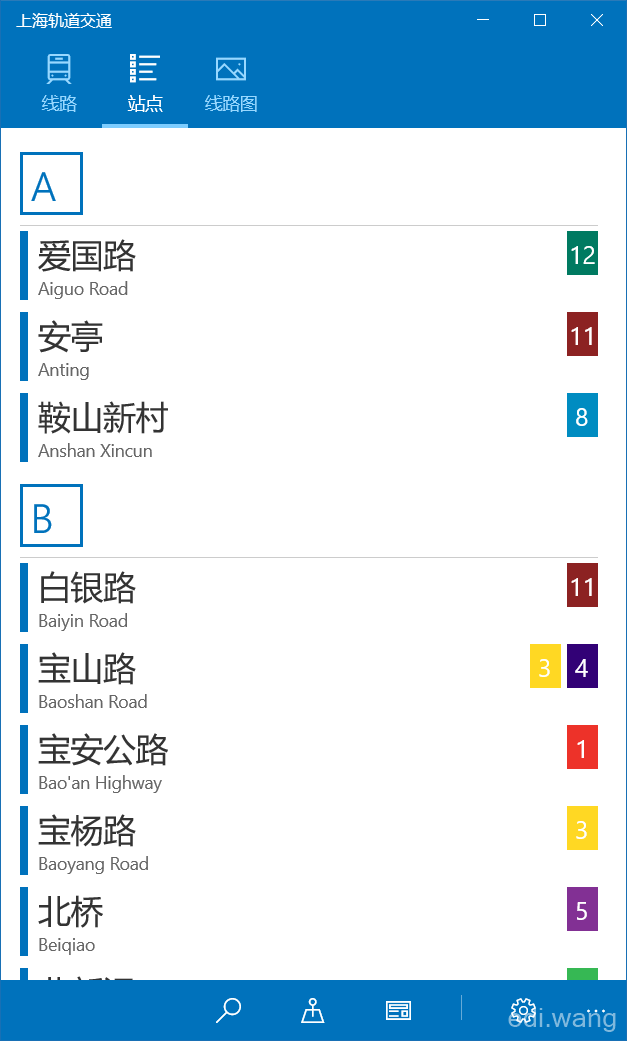
分组:
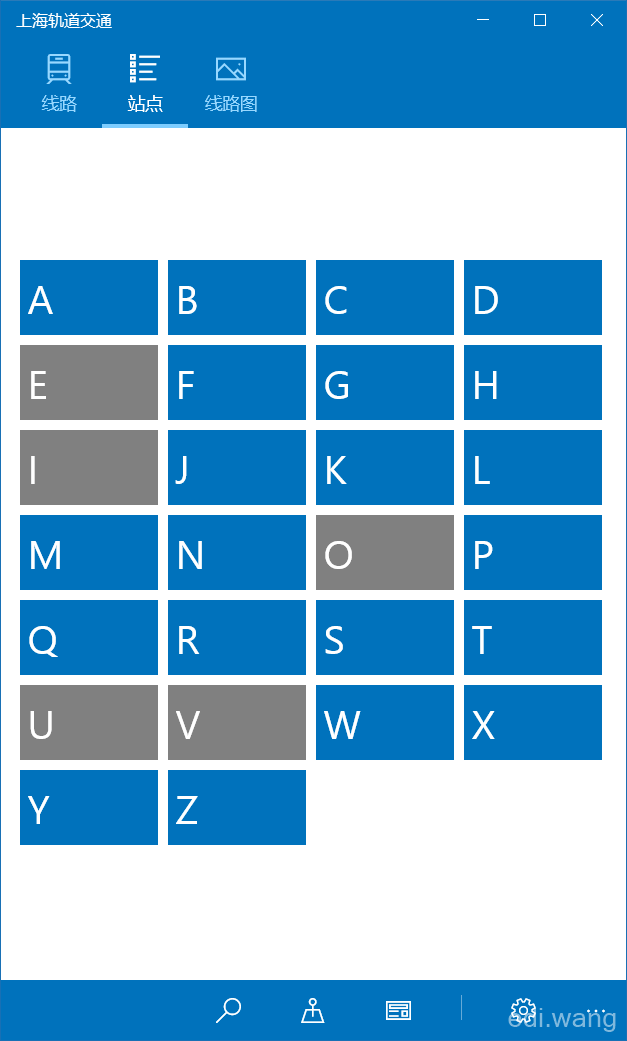
完整代码如下,伸手党可以直接复制了使用:
using System;
using System.Collections.Generic;
using System.Linq;
using Windows.Globalization.Collation;
using DBCSCodePage;
namespace Edi.Metro.Common
{
public class AlphaKeyGroup<T> : List<T>
{
const string GlobeGroupKey = "?";
public string Key { get; private set; }
public AlphaKeyGroup(string key)
{
Key = key;
}
private static List<AlphaKeyGroup<T>> CreateDefaultGroups(CharacterGroupings slg)
{
return (from cg
in slg
where cg.Label != string.Empty
select cg.Label == "..." ?
new AlphaKeyGroup<T>(GlobeGroupKey) :
new AlphaKeyGroup<T>(cg.Label))
.ToList();
}
private static List<AlphaKeyGroup<T>> CreateAZGroups()
{
char[] alpha = "ABCDEFGHIJKLMNOPQRSTUVWXYZ".ToCharArray();
var list = alpha.Select(c => new AlphaKeyGroup<T>(c.ToString())).ToList();
return list;
}
public static List<AlphaKeyGroup<T>> CreateGroups(IEnumerable<T> items, Func<T, string> keySelector, bool sort)
{
CharacterGroupings slg = new CharacterGroupings();
List<AlphaKeyGroup<T>> list = CreateAZGroups(); //CreateDefaultGroups(slg);
foreach (T item in items)
{
int index = 0;
string label = GetCharSpellCode(keySelector(item)); //slg.Lookup(keySelector(item));
index = list.FindIndex(alphagroupkey => (alphagroupkey.Key.Equals(label, StringComparison.CurrentCulture)));
if (index > -1 && index < list.Count) list[index].Add(item);
}
if (sort)
{
foreach (AlphaKeyGroup<T> group in list)
{
group.Sort((c0, c1) => keySelector(c0).CompareTo(keySelector(c1)));
}
}
return list;
}
//http://www.cnblogs.com/glacierh/archive/2008/08/25/1276113.html
/// <summary>
/// 得到一个汉字的拼音第一个字母,如果是一个英文字母则直接返回大写字母
/// </summary>
/// <param name="cnChar">单个汉字</param>
/// <returns>单个大写字母</returns>
private static string GetCharSpellCode(string cnChar)
{
long iCnChar;
byte[] ZW = DBCSEncoding.GetDBCSEncoding("gb2312").GetBytes(cnChar);
//如果是字母,则直接返回
if (ZW.Length == 1)
{
return cnChar.ToUpper();
}
else
{
// get the array of byte from the single char
int i1 = (short)(ZW[0]);
int i2 = (short)(ZW[1]);
iCnChar = i1 * 256 + i2;
}
//expresstion
//table of the constant list
// 'A'; //45217..45252
// 'B'; //45253..45760
// 'C'; //45761..46317
// 'D'; //46318..46825
// 'E'; //46826..47009
// 'F'; //47010..47296
// 'G'; //47297..47613
// 'H'; //47614..48118
// 'J'; //48119..49061
// 'K'; //49062..49323
// 'L'; //49324..49895
// 'M'; //49896..50370
// 'N'; //50371..50613
// 'O'; //50614..50621
// 'P'; //50622..50905
// 'Q'; //50906..51386
// 'R'; //51387..51445
// 'S'; //51446..52217
// 'T'; //52218..52697
//没有U,V
// 'W'; //52698..52979
// 'X'; //52980..53640
// 'Y'; //53689..54480
// 'Z'; //54481..55289
// iCnChar match the constant
if ((iCnChar >= 45217) && (iCnChar <= 45252))
{
return "A";
}
else if ((iCnChar >= 45253) && (iCnChar <= 45760))
{
return "B";
}
else if ((iCnChar >= 45761) && (iCnChar <= 46317))
{
return "C";
}
else if ((iCnChar >= 46318) && (iCnChar <= 46825))
{
return "D";
}
else if ((iCnChar >= 46826) && (iCnChar <= 47009))
{
return "E";
}
else if ((iCnChar >= 47010) && (iCnChar <= 47296))
{
return "F";
}
else if ((iCnChar >= 47297) && (iCnChar <= 47613))
{
return "G";
}
else if ((iCnChar >= 47614) && (iCnChar <= 48118))
{
return "H";
}
else if ((iCnChar >= 48119) && (iCnChar <= 49061))
{
return "J";
}
else if ((iCnChar >= 49062) && (iCnChar <= 49323))
{
return "K";
}
else if ((iCnChar >= 49324) && (iCnChar <= 49895))
{
return "L";
}
else if ((iCnChar >= 49896) && (iCnChar <= 50370))
{
return "M";
}
else if ((iCnChar >= 50371) && (iCnChar <= 50613))
{
return "N";
}
else if ((iCnChar >= 50614) && (iCnChar <= 50621))
{
return "O";
}
else if ((iCnChar >= 50622) && (iCnChar <= 50905))
{
return "P";
}
else if ((iCnChar >= 50906) && (iCnChar <= 51386))
{
return "Q";
}
else if ((iCnChar >= 51387) && (iCnChar <= 51445))
{
return "R";
}
else if ((iCnChar >= 51446) && (iCnChar <= 52217))
{
return "S";
}
else if ((iCnChar >= 52218) && (iCnChar <= 52697))
{
return "T";
}
else if ((iCnChar >= 52698) && (iCnChar <= 52979))
{
return "W";
}
else if ((iCnChar >= 52980) && (iCnChar <= 53640))
{
return "X";
}
else if ((iCnChar >= 53689) && (iCnChar <= 54480))
{
return "Y";
}
else if ((iCnChar >= 54481) && (iCnChar <= 55289))
{
return "Z";
}
else return ("?");
}
}
}